Table of figures
O código já está praticamente feito. Embora os bugs e as ideias de melhoria nunca parem, no essencial faz o que quero. A beleza deste código é que corre localmente a partir de python e não guarda quase nenhuma informação em si. A única informação são os ficheiros guardados para mais tarde, a cache com metadados e a directoria por defeito. Por outras palavras, o código ajusta-se à organização que o utilizador tem actualmente em vez de ser o contrário.
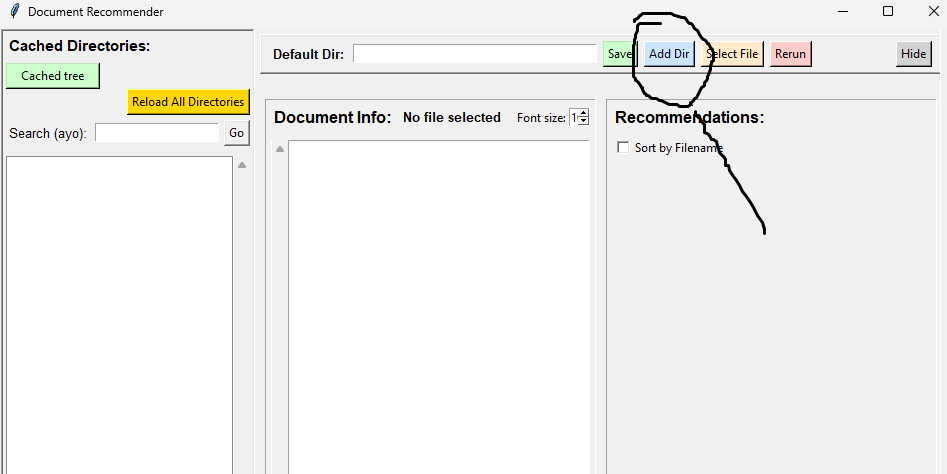
Quando se arranca pela primeira vez pede directorias para carregar na cache.
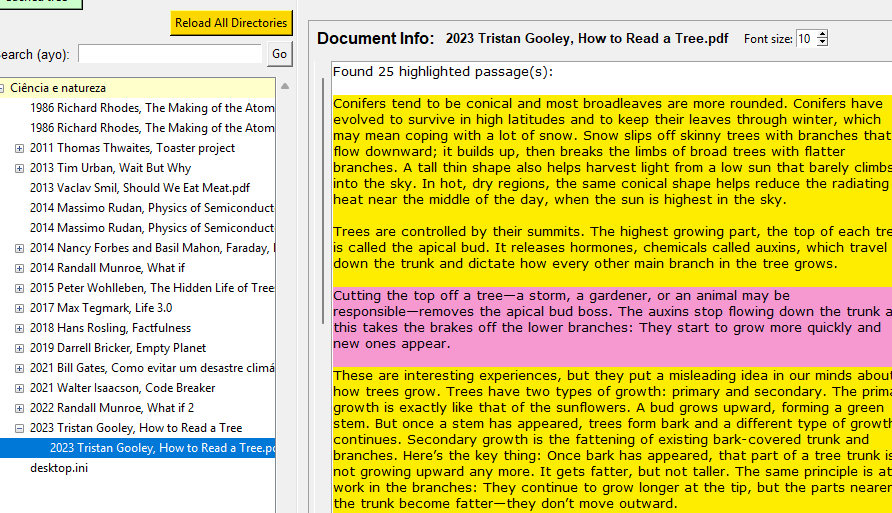
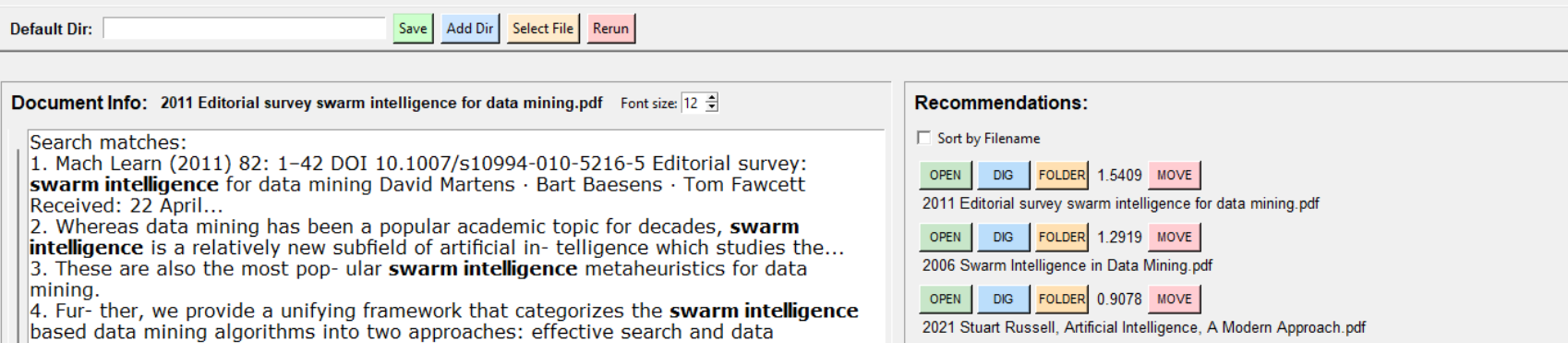
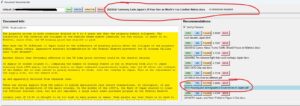
Quando um ficheiro é seleccionado, são mostrados os trechos realçados para que o utilizador não precise de abrir um ficheiro só para ver o que sublinhou.
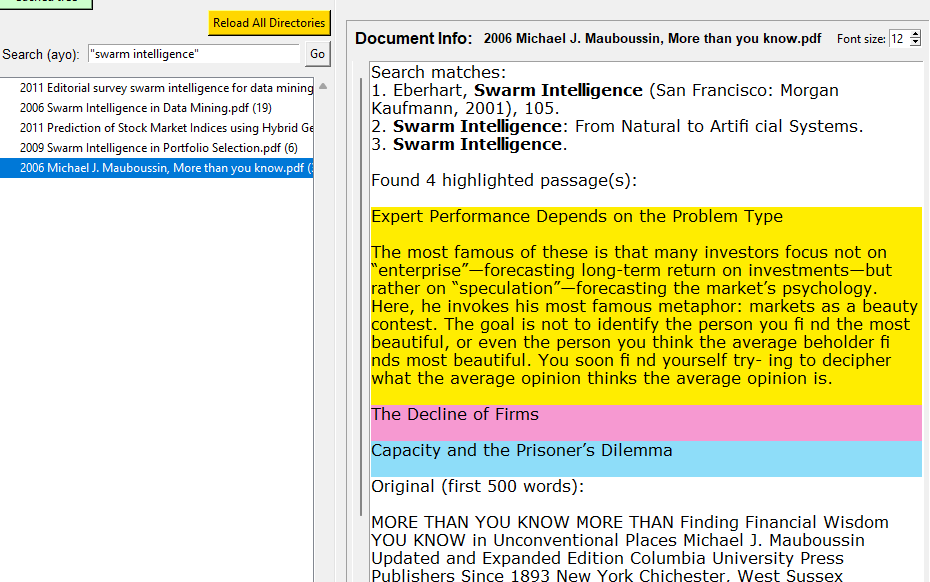
Se o utilizador usar a busca, por cada ficheiro encontrado são mostradas as frases em que esses termos foram encontrados. Isto a mim facilita muito, para não ter de abrir um ficheiro só para ver que afinal o termo encontrado não tem nada a ver com o que quero.
O utilizador também pode usar o método cosin para encontrar ficheiros semelhantes. Eu diria que este método é bom o suficiente para encontrar ficheiros parecidos e não é bom demais para nunca sugerir ficheiros estranhos.
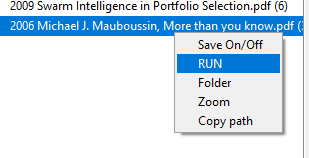
E assim são mostrados os ficheiros que neste caso são semelhantes a Editorial survey… na sidebar direita.
O código corre a partir de uma cache que fica guardada na mesma directoria em que este está.
 Eu na altura da dissertação usava o Evernote e depois fiquei destroçado quando começaram a apertar nas subscrições e até o desempenho foi piorando.
Eu na altura da dissertação usava o Evernote e depois fiquei destroçado quando começaram a apertar nas subscrições e até o desempenho foi piorando.Depois disso usei o KeepNote, que era uma app portátil grátis. Ao fim de uns anos tornou-se impraticável, porque tinha imensos freezes à medida que a informação ia aumentando e estava totalmente formatado para processar somente html.

Deixe um comentário